引子
今天要真的“弄斧”一波了,谈谈游戏中的AI。
电子游戏中的AI、电脑玩家是很多玩家非常熟悉的一类角色,往往陪伴着我们从一个游戏小白逐渐成长为一个游戏高手,在这个过程中孜孜不倦地作为我们的陪练对象、游戏沙包。
可以说几乎所有游戏中都存在一些AI性质的内容,可能是“令人发狂的电脑”,可能是单机RPG里非玩家操作的队友,也可能仅仅是网游中的NPC。
近年来,随着人工智能技术的不断发展,尤其是在谷歌的Alphago在围棋的人机对战中大放异彩后,很多玩家开始畅想未来的游戏中会不会有了“像人一样”的AI角色充当自己的助理、队友甚至于对手,而那又将会是一种怎样的体验?
暴雪在WOW8.0里的“海岛玩法”中将加入由AI控制的“高级NPC”作为玩家的对手
《魔兽世界:争霸艾泽拉斯》前瞻:海岛探险-视频(https://www.bilibili.com/video/av21701600)
但另一方面,绝大多数玩家并不清楚游戏中AI的实际工作原理,以及做一个“像人一样”的AI觉得到底需要付出怎样的代价,所以今天要就要谈谈游戏中的AI到底是什么。
但由于本人并未直接从事过这方面的相关工作,只是在工作学习中有一定的接触和了解,所以只能尽可能地站在理论分析的角度,谈谈AI技术在游戏行业中现状以及未来发展,不涉及具体的实现细节,如有错误还请斧正。
老一辈的脚本AI
游戏中的AI那是有着悠久的历史了,可以说只要游戏中不是只有“玩家”这一种变量,那么另一种变量就是一种AI的表现形式,最常见的例子就是玩家所要对抗的“敌人”,毕竟绝大多数游戏中都是有敌人存在的。
但是虽说都是敌人,都可以算AI,但是也有高低贵贱之分。最低级的AI都几乎不能被称之为AI,因为其行为方式是完全固定,没有一丁点变化,典型的例子就是FC版超级马里奥里的板栗仔(蘑菇仔)、乌龟等等怪物,只会傻头傻脑地朝着一个方向走,碰到墙壁掉头而已。
“稍微”高级一点的AI能引入了一些随机的因素,比如超级玛丽里扔锤子的乌龟,其扔锤子、起跳的时间带有一定的随机性,让玩家不好预判。
可以说老式游戏中敌人的AI都是上述2种方式的组合,例如文曲星上的“困兽斗”里的怪物既会进行一定的随机走位,也会在玩家垂直移动时向玩家的方向移动(所以玩这个游戏时走到角落里疯狂按下就能把吸引过来),本质上就是一段固定的程序脚本。
但是显然这种很简单的行为模式就太容易被玩家摸透了,糊弄糊弄小孩子还行,稍微聪明点的玩家很容易发现其中的规律,也就失去了斗智斗勇的乐趣。因此,让游戏中的敌人的行为带有一定的“策略”性,同时将行为的模式复杂化就成为了必然的选择。一方面行为策略使得怪物的行为显得合乎道理,而复杂的模式变化(数量、类型)使得怪物的表现形式不再单一。
例如“吃豆人”游戏中的4个“幽灵”怪物就分别有自己的行为模式:红色的一直跟在玩家屁股后面的,粉色的以玩家行进路线的下一个路口为目标,蓝色的则再进一步,以下一个路口后的路口为目标(预判),最后橙色的完全随机行动。
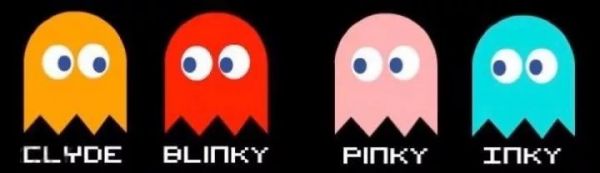
吃豆人里的4个怪物
多数量、多类型的怪物使得玩家在初次接触游戏时不那么容易摸清楚敌人的行为方式。而即使摸清楚了,想要在这种复杂的环境下从容取胜也不是那么容易,因为需要同时预判多个怪物之后的路径。最后辅以不同关卡下不同敌人的移动速度不同,从而使得游戏有了丰富的变化和体验。
不过,虽然怪物的行为方式有了变化,但是行为目的还是太过单一。在吃豆人这种小格局的游戏中还好,因为本来就只有“抓住玩家”这一个目标,但到了目标更加复杂的游戏中,例如策略类游戏,那么仅仅只按照一个预定好的目标一致走下去显然还是过于“蠢”了。玩家希望游戏中的敌人表现得更加灵活多样一些,例如会在打不过时逃跑,会根据玩家的行为作出针对性的应对等等。
于是,以有限状态机、行为树为核心的游戏AI模式出现了。
有限状态机与行为树AI
这2个词对没学过程序设计的朋友来说可能十分陌生,但其本质很好理解,就是很多个“if-else”判断语句的组合,只是在大型游戏程序中,为了开发、修改的便利,对这些if-else进行了包装,形成了2种不同的套路。
所谓状态机就是以电脑AI的“当前状态”为主体,通过编写不同状态之间的转换条件从而控制电脑AI的行为。例如在巡逻状态中如果发现敌人则转移到报警状态,而如果听到警报则进入迎敌状态。剩下就只需要撰写巡逻状态、迎敌状态、报警状态下分别有怎样的行为目标、策略以及具体做什么就行了。
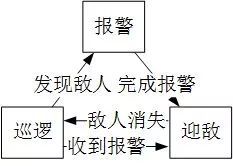
而行为树则以电脑AI的“行为”为主体,通过编写判断条件,使得电脑AI每一次询问“我现在该干啥?”时通过一系列的判断得出“现在应该XXX”的结论。例如先判断周围是否有敌人,如果有敌人则判断是否已经进行过报警,如果没报警则报警,如果已报警则迎敌。剩下就是写每一个行为中的具体行为策略和行为内容。
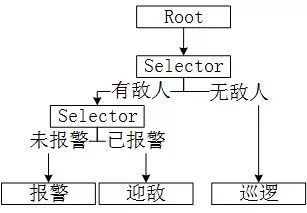
2种设计、编程模式各有优劣,但通过上述分析可以看出,其本质都是游戏设计者在编写AI的代码时已经提前预设好的各种策略、行为的组合,而且通常情况下是非常死板的。这也是为什么绝大多数游戏中的AI都会给人“操作很厉害,但是很蠢”的原因,因为操作是直接通过游戏内部的代码实现的,自然在反应、多操上强无敌;但由于策略是固定的,因此战术死板、不懂变通、千篇一律,无法应对一些非常规战术,显得很“蠢”。
虽然这种游戏AI的编写方式虽然已经可以做到非常复杂、强大,但是毕竟是由设计者提前设计好的,而设计者不可能做到面面俱到,总会有一些特殊、诡异的场景没有放到状态机、行为树中,从而形成“漏洞”。一旦玩家摸清了AI的规律,或者发现了设计者没有考虑到的情形,就可以利用这些漏洞玩出花样,轻则速通,重则触发各种诡异的BUG。
例如红警2中玩家不展开基地车电脑就不会造兵,因此玩家可以直接使用初始兵力利用操作打败电脑的初始兵力直接获胜(苏联最后一关甚至可以以此直接使用初始给的基洛夫空艇过关)
例如星际1中电脑完全不会应对堵口战术,操作得当的话靠着这招可以做到1vN
例如WAR3中使用TR战术可以Rush掉任何难度的电脑,包括几乎所有可建造的战役关卡(除了海加尔山这种敌人强无敌的关),操作得当1V2都不是问题
机器学习AI
到了最近的3-5年,机器学习技术的发展使得“人工智能”这个词在科技界和工业界变得炽手可热。从以苹果的siri、微软的kotana为代表的语音智能助手,到现在卖得不错的智能音箱,似乎实现“人工智能”已经不再是遥不可及的一件事。
但是请关掉你脑中已经出现的各种科幻电影、游戏中出现的人工智能机器人的画面,例如《星战》系列里R2D2、3PO,《光环》系列游戏里的科塔娜,因为就目前的电脑技术而言,真正实现一个具有自我意识、感情,“像人一样”的人工智能还是遥不可及的一件事,现在的“人工智能”距离大众理解中的“人工智能”还有相当长的一段距离

星球大战中的R2D2和3PO
现阶段“人工智能”的本质是通过机器学习技术让计算机能够不依赖人工指导和干预,自发地解决实际生活中复杂、多变问题的能力,例如将语音转换为文字,根据文字执行对应指令。但这其中并不真正包含“智能”的成分,只是通过大量数据的训练,得到了一个“判别模型”,这个模型对于任意输入数据(例如声音、图片)能够输出对应的判别答案(例如声音对应的什么文字、图片是猫还是狗),但至于为什么,电脑并不知道,甚至很多情况下连模型设计者也不知道。
其实“人工智能”的训练过程和驯兽师训练动物很相似,做对了给奖励,做错了有惩罚,在大量的训练之后,动物就知道什么情况下应该做什么,不应该做什么了。但是动物并不一定知道为什么应该这么做,只是知道这么做是对的。
以著名的Alphago为例,Alphago通过前期超大规模的模拟对局和已有的棋谱进行训练(Alphago Zero已不需要棋谱),得到了一个以“当前局面”为输入,“下一手落子位置”为输出的模型,因此在实际对局中利用这个模型能根据当前局面做出判断,不断下棋。但是和人能讲出为什么应该这么下不同,这个模型本身并不能解释其判断的原因。
其实这个道理很好理解,因为人自己都不知道自己是如何思考、得到结论的,以神经网络及其扩展算法为例,算法通过模拟大脑神经元之间互相刺激产生输出的过程来进行学习,但是别说工程师了,研究大脑的科学家对人脑目前都没有研究清楚呢,神经网络算法不过是以神经系统的特性为灵感而设计出的算法,并不代表神经网络算法得到的模型就和人脑的思维方式是一样的。
当然这里我们不谈机器学习的算法细节,谈谈在游戏AI领域机器学习所面临的问题和挑战。
首先是输入数据的维度问题。
机器学习过程中,数据的维度是指一条数据中包含多少项细节数据。
以围棋为例,棋盘共有19*19=361个交叉点,因此要完整地描述“当前棋盘的状态”,就需要说清楚这361个点各自处于什么状态,那么这一条数据应该包含361个取值为0、1、2的数,0代表这个没有子,1代表是黑子,2代表白子,于是我们说围棋的数据维度有361维(仅仅是举个例子,实际可能并不是这么表示的)。
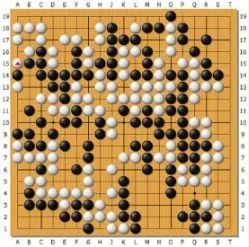
机器学习训练出的AI需要通过这些输入数据判断出当前情况下应该怎么做,显然输入数据的维度越多,整个模型训练和使用的过程就越复杂(得到模型所需要的训练时间和实际使用中判断当前状态需要怎么做所需要的时间都会更长)。
在围棋中,使用361个数就能完整描述“当前游戏状态”了,但在电子游戏中,要描述“当前游戏状态”到底需要多少个数?上千上万是很可能的,例如RTS游戏中双方每个小兵的位置、血量、当前状态等就需要上百个数字,更不提还有基地状态、地图状态等等。
但是并不是“所有”数据都是有用、必要的,某些数据可有可无(野怪身上的buff),某些数据可以合并(只需要记录家里有几个农民在采矿,不需要记录具体每个农民的状态),这些事情是需要一定程度的人工干预的,但如何取舍、精炼这些数据,目前还缺少可靠的方法。
第二点是判断时间。
不像围棋一手可以考虑好几十秒甚至数分钟,游戏中的操作间隔都是以毫秒为单位的,顶尖游戏玩家、职业选手的APM(每分钟操作数)能达到200、300以上,换算下来就是几毫秒就要操作一次。
因此如果要通过机器学习AI来实现对游戏中所有操作的判断,即每一次操作都是模型对由当前游戏状态的判断得到的,那么每一次判断所需要的时间必须在几十毫秒这个量级上,否则一些关键操作(闪现躲技能)是无法实现的,这对于一些游戏状态复杂度极高的游戏来说难度极大。
例如绝地求生中光描述周围的环境就不知道要多少维数据,同时FPS游戏中虽然APM较低,但反应时间要求极快,AI需要在十几毫秒内做出是跑还是打、打谁、怎么打的判断。
第三点是训练方式。
机器学习的训练分为2种,一种是通过“左右互搏”的方式在模拟对战中自己跟自己玩,根据模拟对战的胜负来指导“什么是正确的做法”“什么是错误的做法”。另一种是通过实际人类对战的数据来进行训练,告诉机器“人是怎么做的”“怎么做能获胜”。
从目前的论文上看,在实验中已经实现的游戏(围棋、打砖块、推箱子等)中,“左右互博”的强化学习(Reinforcement Learning)方式似乎获得了更好的效果,但这些游戏都无需依赖其他外部输入,实现高效的模拟对战。但随着游戏复杂度的提升,模拟对战变得越来越低效,如果不与开发商合作得到游戏的高效模拟平台(在AI自动化操作的情况下超快速度进行游戏),那么一局模拟对战的时间就太长了,对于训练模型所需要的动辄上千万次的模拟对战来说,这样的训练时间是无法接受的。
而另一种通过实际人类对战的数据进行训练的模仿学习(Imitation Learning)则很受限于使用到的数据的完备性,是否覆盖到可能的各种战术、各种情况,否则就可能造成训练出的AI出现“偏科”的情况。而且说实话,人的决策也不见得就是最佳的。
目前来看,使用机器学习进行AI训练最鲜活的例子是于2017年DOTA2国际邀请赛上亮相的由OpenAI公司训练出的DOTA2 1V1 SOLO AI,在表演赛中以几乎碾压的形式战胜了著名DOTA中单选手Dendi
该AI在补兵、控线、和技能释放上几乎做到了完美,显示出了电脑AI在血量计算、距离把控上天生的优势。
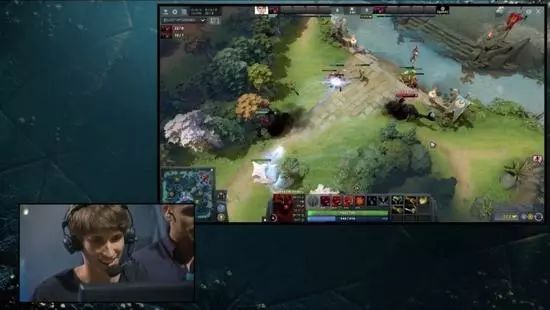
图中AI操作的红色血条的影魔完美地站在防御塔的攻击范围边缘对Dendi进行着压制
但由于这个AI是通过左右互博的方式训练的,于是在后来的玩家挑战赛中,玩家通过绕后勾兵等“奇葩战术”把这个AI耍得团团转。
个人认为,在游戏领域的AI设计中,一招通吃是不现实的,不能指望训练出一个模型就通杀游戏中方方面面的判断和操作。
因为稍微有点深度的游戏就已经相当复杂了,其训练难度、判断难度都十分高,想要实现一招通吃所需要的模型太过复杂。另一方面,游戏中并不需要进行“大一统”的判断,全局的战略和局部的操作是存在一定的割裂性的,例如RTS游戏中前线打架时并不需要考虑基地中农民的状态,而下一步应该造什么兵的判断标准也和当前前线士兵的血量无关只和当前的整体战局相关。
实际上真实玩家也是如此,例如MOBA游戏中有的人大局观好,知道什么局面出什么装备选什么战术,但操作一塌糊涂,也有人反过来对线猛如虎,中期梦游送人头。
另一方面,游戏中的操作并非一定要考机器学习的AI去直接进行,补刀、采矿、建造等行为是可以通过固定的脚本实现的,机器学习的AI只需要做出“目标判断”,剩下的事情可以靠脚本实现。
一定要机器学习?
由于今年来机器学习和人工智能的火热,当谈到游戏中的AI时,很多玩家总会感到莫名的兴奋,希望自己所玩的游戏里也能有类似人工智能的AI对手。但实际上虽然机器学习确实在很多领域(例如语音识别、智能推荐)中获得了不错的效果,但其在游戏领域则很可能“水土不服”。
首先必须明确的是,并不是所有游戏都需要游戏中的AI“像人一样”。
不同游戏对玩家的要求是不同的,有的侧重于个人操作、反应例如ACT游戏,有的要求玩家团队配合默契、分工明确,例如MMORPG里的副本战,有的希望玩家能够带有沉浸感地体验游戏中的虚拟世界,例如很多单机RPG
因此在一些游戏中,行为固定、死板的敌人就是设计目的的一部分,例如WOW里的BOSS都有着十分固定的行为方式,从仇恨系统到技能时间轴到转阶段流程等等,因为BOSS战本来就是考验团队在巨大的实力不平衡下通过团队的配合利用BOSS行为死板的特性战胜它,要是BOSS真的智能到上来先秒治疗再秒输出最后蹂躏坦克,那还玩个毛啊

“死吧,虫子!”
第二,即使是死板的AI脚本,在长时间不断完善的情况下依然能够取得很好的效果。
前面提到过的那些死板的AI撰写方式,其死板的根源是设计者无法在设计之初就考虑到各种情况。这在以往的游戏,尤其是单机游戏中确实是一个比较明显的问题。但如今随着网络的普及,即使是单机游戏也有各种在线更新机制,更不提现在网络对战游戏的火热,AI并不是一定自出厂后就只能一成不变,游戏设计者可以不断完善,甚至可以开放接口让玩家自己编写AI
DOTA2的机器人脚本就是一个例子,通过封装、公开API接口,让玩家自行撰写机器人AI脚本,甚至还可以组织AI脚本比赛“养蛊”
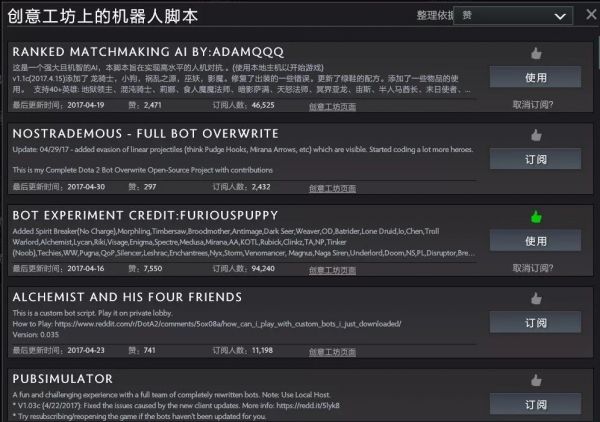
第三,和Alphago设计出来就是为了战胜人类不同,对于游戏公司来说游戏中AI并不是一味地强就好,FPS游戏中AI可以做得远胜于人类,因为在“射击”这个行为中AI的反应时间和瞄准精度都可以高到离谱。但是这样的AI对于玩家来说没有意义,除了部分追求极限的玩家可以作为挑战自己的工具外,对其他玩家来说一文不值,谁愿意跟一个自瞄锁头的挂逼对战呢?
因此游戏中的AI在制作、训练的过程中并不是越强越好,而是越像人越好,和人一样在紧张下会失误、被击中后不知道对方在哪里、射击不精准的AI才是大部分玩家在对战中希望碰到的AI,过强或者过弱的AI都是不可取的。
最后,机器学习训练出的AI在使用中对计算量的需求是十分大的,网络游戏里的AI运算还能靠服务器解决,如果单机游戏中由于引入类似的AI导致游戏卡顿,那就真是丢了西瓜捡了芝麻的蠢事了。
而且即使是能够靠服务器解决运算问题的网络游戏,单个BOSS的场景还好,真要将世界地图中的野怪、NPC都“人工智能”一下,游戏公司开不开心我不知道,收电费的肯定会很开心。
结语
机器学习技术的发展给了历史悠久的游戏AI打开了一个全新的大门,很多玩家也十分憧憬游戏中能有AI的加入从而改善自己的游戏体验(至少AI不会骂人、送人头)。
但就目前而言,将机器学习技术应用到游戏AI里还有许多问题需要解决,游戏AI的设计也不仅仅是把机器学习技术照搬照用这么简单。
但是必须肯定的是,随着未来计算机硬件的发展和机器学习技术的完善,游戏AI会迎来一波革命式的发展,对各类对抗性质的游戏带来翻天覆地的变化。
参考阅读:
在DOTA2中获胜的AI真的比AlphaGo厉害吗?(http://36kr.com/p/5087845.html)
马斯克的OpenAI是如何击败dota2顶级人类选手的(http://tech.163.com/17/0814/11/CRQ0EHI800097U80.html)
给猫看的游戏AI实战(三)基于状态机的AI系统(https://zhuanlan.zhihu.com/p/28654527)
游戏 AI 进化史,能阻止 AlphaGo 的或许只有狼人杀了(http://news.163.com/18/0304/09/DC1VASD9000197V8.html)返回搜狐,查看更多
责任编辑:








